
Today we will start a new series of posts about the MangaDex API. We aim to present some of the challenges and considerations we have had while building v5 API. We will have an overview of the security, data storage and access layers.
Before...
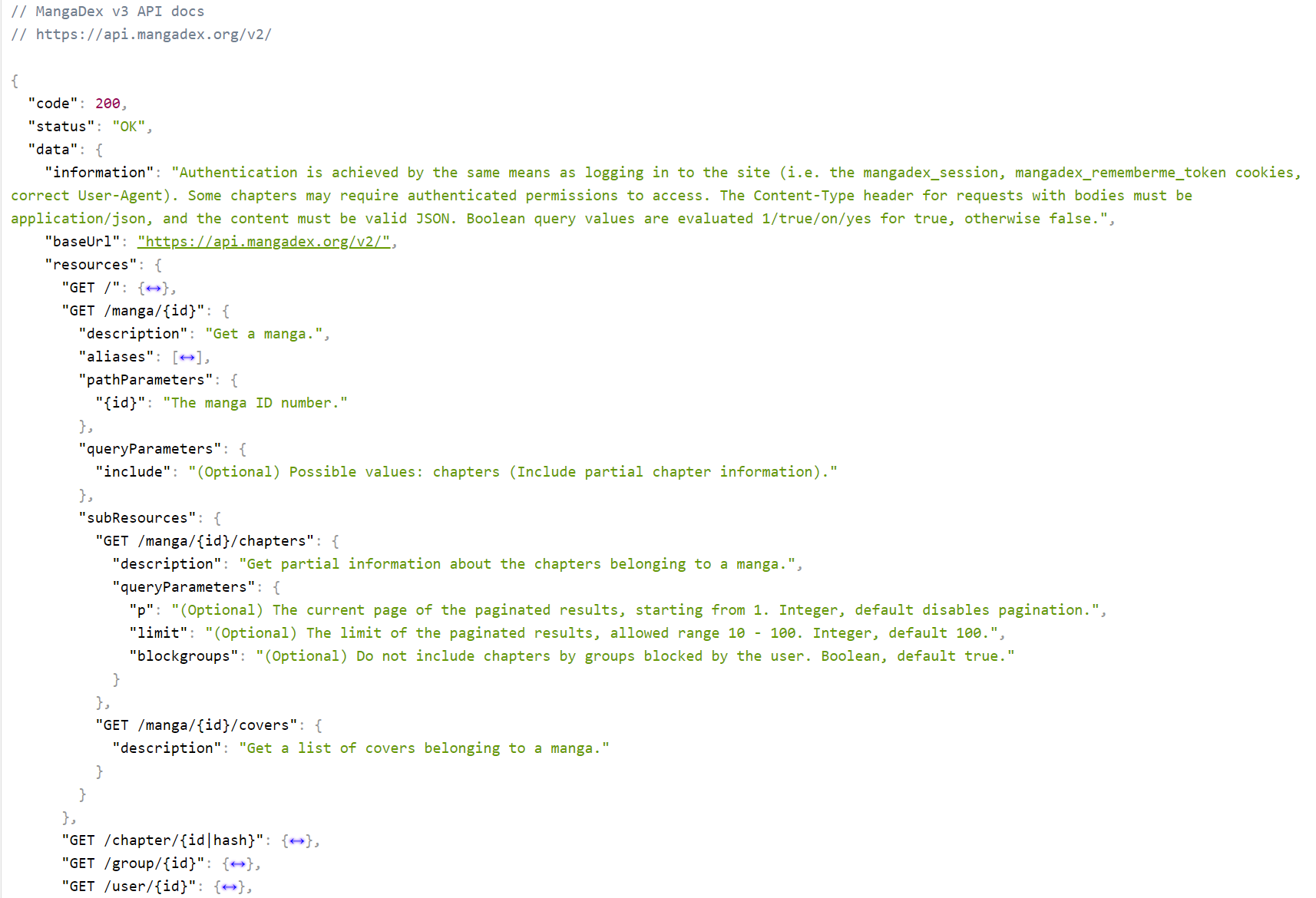
Before MangaDex v5 was MangaDex v3.
Taken from an old PHP torrent tracker's codebase and updated following ad-hoc development practices, it had no template engine, used raw HTML with PHP tags in the markup1, had no SQL access library to avoid potential SQL injections, and all the other issues you could think of from a framework-less ageing codebase built while learning the ropes of software engineering.
While it served us appropriately and had been updated to run on the very last patch version of PHP 7 (which was the latest and greatest at the time) and thus avoided some of the PHP5 security issues of its beginnings, it was still already on its last legs and just keeping it alive was more difficult with every day that passed.
A first attempt at modernizing the platform, named MangaDex v4, used the existing codebase but tried to revamp the UI, integrate Elasticsearch into its backend and generally modernize the codebase by porting parts of the code to Symfony components like routing, dependency-injection and a more structured request/result handling. However, just like PHP62, it never came to fruition.
Work on a future platform eventually started a second time, as v3 grew even more difficult to maintain. It was MangaDex v5 and it would get things right. That was already ongoing before the leak of the codebase in March 2021, but development time for it was competing with the time needed to keep the existing site up at all at the time, and it was progressing slowly. One of the early experiments was a NodeJS API proof of concept, but it was eventually decided to keep going with PHP for many reasons ranging from familiarity with the platform within the staff to a more flexible approach to permission management with Symfony.
Then in March 2021, we became aware that our source code leaked to the public, and that our backend was compromised. A lot of effort was spent to audit the code and plug holes, but in the end a hard decision was made to shut down the site, scrap the old code and start fresh, finally making the rewrite happen. We chose PHP and the Symfony framework because active developers were accustomed to it and it provides an industry-grade bedrock to build the API on, with high popularity and a high chance to find developers in the future. When you build a project, whether for yourself or at work, you should keep in mind what skills your team has before choosing a language or framework. Having something people are used to and that has correct community support will always produce better results.
Let's get started
While the website was still down, we were planning towards a fast reopening by making a shortlist of features to get ready first, to have an MVP (minimum viable product) up as quick as possible:
- Searching for a title
- Title and Chapter feeds
- Users and Follows/Custom Lists
- Groups and Authors
We started finally making serious progress on the v5 API by mid-March, with the first private beta on April 12th and the public opening on May 11th. So it took us approximately 2 months to have both API & new infrastructure ready and working after it was decided to give up on v3. This was a big milestone, the third-party contributors (Tachiyomi, Paperback and SauceNAO) that had participated in the private beta gave us great feedback which helped a lot.
We are still in the process of catching up to full v3 feature parity, but we are getting ever closer, and already with some entirely new features and incomparable stability. While it's not always visible, a lot of work happens behind the curtain for this. For example: recently we reintroduced title relations and ratings, which took a lot more work to get right on our backend before it could be exposed publicly and used in our frontend. It is important for us to build on a solid structure that will hold the test of time, even with the limited hardware resources we have at our disposal. Being smart and dedicated about optimization is generally something we have to be wary of and invest in at every step of the way.
Security
Since most of our features are free and open to anyone, we put a strong focus on security, to avoid malicious usage of our API.
Before a request hits our API servers, there are several security layers in our infrastructure. First of all, we use ModSecurity, a popular open-source WAF with the OWASP's CoreRuleSet to defeat most generic attacks (not that the API would be vulnerable to anything we've seen it catch so far, but it makes it much more difficult for an attacker to even reliably test an attack at all). We tweak and add our own rules and exceptions on top of it to accommodate MangaDex's user-generated nature.
Now that we have done most of what we could do with infrastructure, let's talk about the application layer. Thanks to Symfony's security component, we can easily manage everything related to authentication and authorization. It will decide how your request will be authenticated³. That component is also made with several ways to extend it, that we currently use to add the JWT token authentication on our API.
We restrict all endpoints to permissions that are assigned based on user Roles, that are managed hierarchically, and we can assign or restrict individual permissions on a per-user basis, which yields a unique list of actions the user is allowed to perform.
security:
role_hierarchy:
ROLE_GUEST: ROLE_BANNED
ROLE_UNVERIFIED: ROLE_GUEST
ROLE_USER: ROLE_GUEST
ROLE_CONTRIBUTOR: ROLE_USER
parameters:
permissions:
ROLE_GUEST:
- 'manga.view'
- 'user.view'
- 'manga.list'
ROLE_USER:
- 'user.list'
ROLE_CONTRIBUTOR:
- 'manga.edit'
This is an example based on our current configuration. It shows the role hierarchy map at the top and how those roles resolve into individual permissions by following the role inheritance. Following this configuration, ROLE_USER will inherit permissions of ROLE_GUEST, so it will have user.list but also manga.view, user.view and manga.list. As it continues to the next role, ROLE_CONTRIBUTOR, the manga.edit permission is added.
We added another mechanism to overwrite permissions on a per-user basis so we can for example restrict the report.create permission for our more persistent users at times. We could even rescind the manga.view permission and deny a user the permission to view title pages entirely.
You could say that is enough security and we would be safe without more, but MangaDex is a website that attracts a lot of people with bad intentions, and we have to additionally protect against misuse within the allowed permission set of normal users.

To avoid rampant botting, we thus require reCaptcha verification for critical endpoints (user creation and report creation). Since you will need to pass the reCaptcha v3 challenge on the mangadex.org domain to use them, it's rather difficult to abuse these at scale without significant costs on the attacker. But we also want our API to be open to everybody and not limited to our own website, so it's used only on such sensitive endpoints that are not critical for general API usage. And even mobile apps that want to rely on them, like Neko, can work around it by redirecting the new users to our website for the sign-up process.
Additionally, rate limits are set globally on our load balancers (to 5 req/s/ip) and further on all endpoints that need stricter control. For example, you can edit a title only 10 times every hour. With this, we can avoid spam globally and on more critical endpoints. You can see all these rate limits on our API documentation.
Finally, we have JSON Schema validation on HTTP request path, query parameters and body. We have a JSON Schema made for each endpoint that describes exactly what is allowed and what isn't, and anything that doesn't match it will be rejected. On top of that, we also estimate what should be the maximum size of your requests per endpoint and added a size limit to all endpoints that have a request body required, so we can also reject requests with larger than expected body sizes.
Async
We have to make our API as fast as possible. In practice, our API's average response time is currently around 50ms.
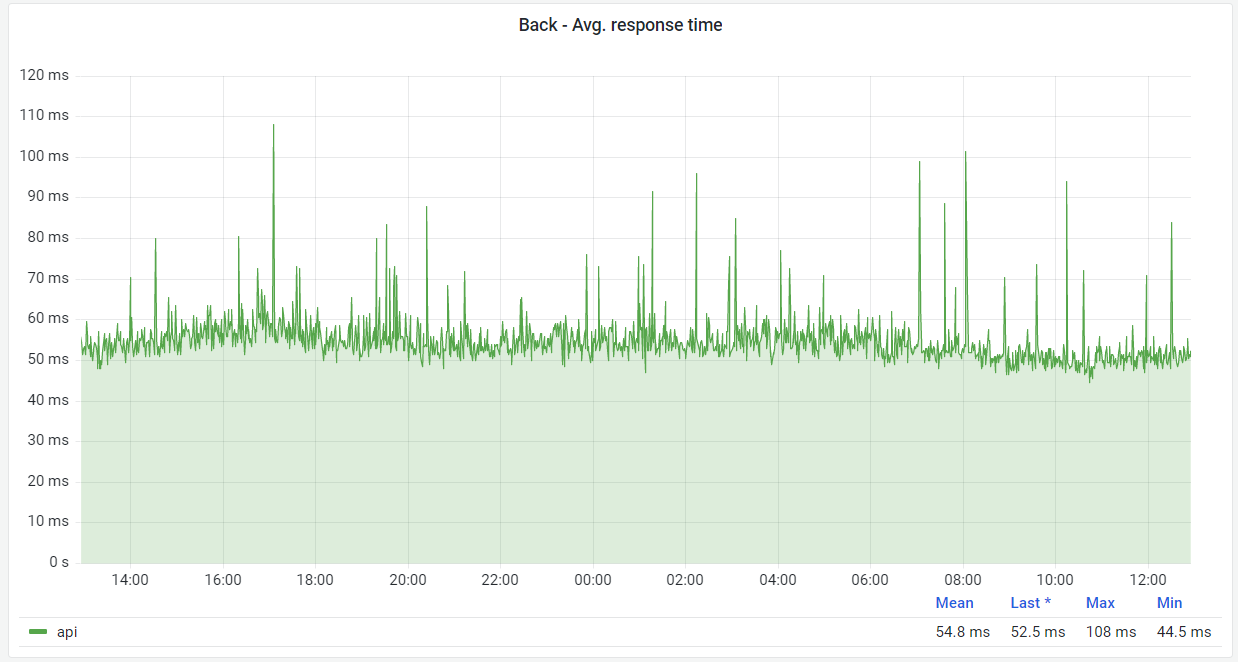
However, due to the global presence of MangaDex, we have a flat latency cost to add on top of it, which we work against by caching at the edge, but not everything can be cached, so it's important to also keep the source fast. This currently results in about 120ms average response time around the world.
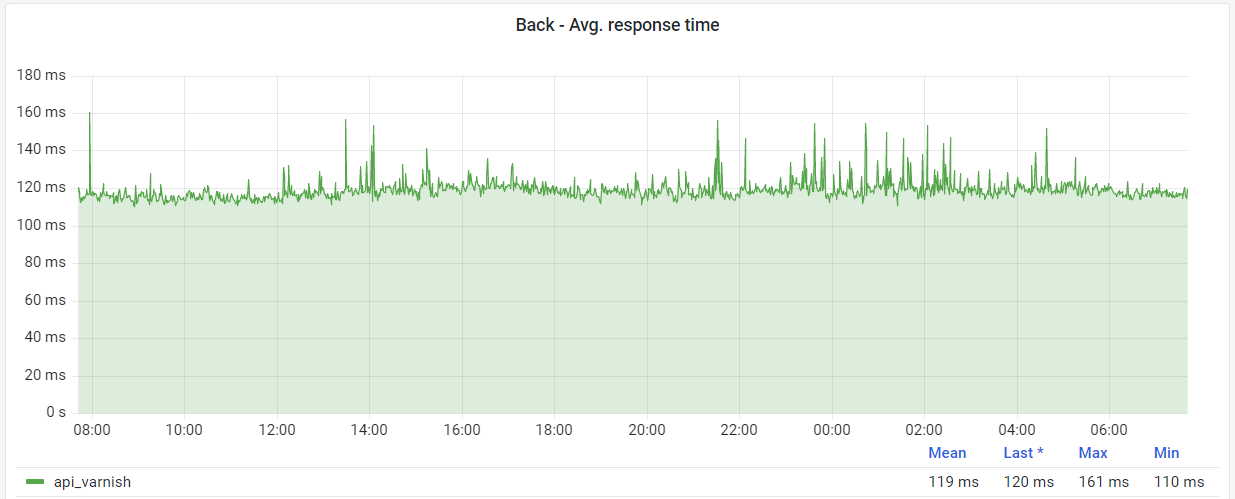
Given the mostly-unchangeable flat cost due to geography, we try to bring the internal response times lower to improve performance. This time varies based on a lot of factors. For example, when asking for a title's data, we reach Redis cache and if that cache is empty we ask Elasticsearch for this data, so we can send the response as soon as possible.
But this doesn't work for processing endpoints such as title edition. For these endpoints, depending on the criticality of the resource, we can sometimes use RabbitMQ (a message broker) to send the command in a queue and reply to the HTTP request even before it was processed, which allows a really fast response (and avoids locking the whole public network route, from the edge to FPM processes⁴ for no reason).

Then the message is eventually handled by a separate worker process that executes the command and all related tasks (update the database records, update Elasticsearch documents, update related entities, evict old data from our edge caches, ...).
This is also why when you edit a title, you need to wait for a short delay (at most 15 seconds at the time of writing) until all of the processing and publication work has succeeded, and the update becomes visible everywhere in the world.
Data & Caching
As you can see from the previous section, a critical area of v5 is the storage and caching we are using. As stated above, we use multiple layers of caching to avoid hitting our primary database (Percona's distribution of MySQL at the moment) if possible.
All the authoritative data is still stored in that database, and we have a read-write primary and read-only replicas deployment⁵ to ensure the best performance possible when we need it, but we still prefer to keep it as last resort, as scaling relational databases meaningfully is a complex exercise.

Then we index all the public data from the database into Elasticsearch indexes. This is something that can take time because of how the large dataset we have. For example, indexing all of the chapters from scratch currently takes up to 6 hours.
To ensure the site stays live and functional while this is ongoing, while the new index is being created, the old one is still used to handle requests. Because its dataset comes from a database table snapshot taken when we start this process, once the snapshot processing and import are done, we have to replay modifications that happened during its preparation, and can then finally make it active. Even though our current system generally works well, we still have a long way to go to optimize this. The indexation process itself takes much more time than we'd like, and we still have occasional issues with the replay of modifying actions once the new index is live.
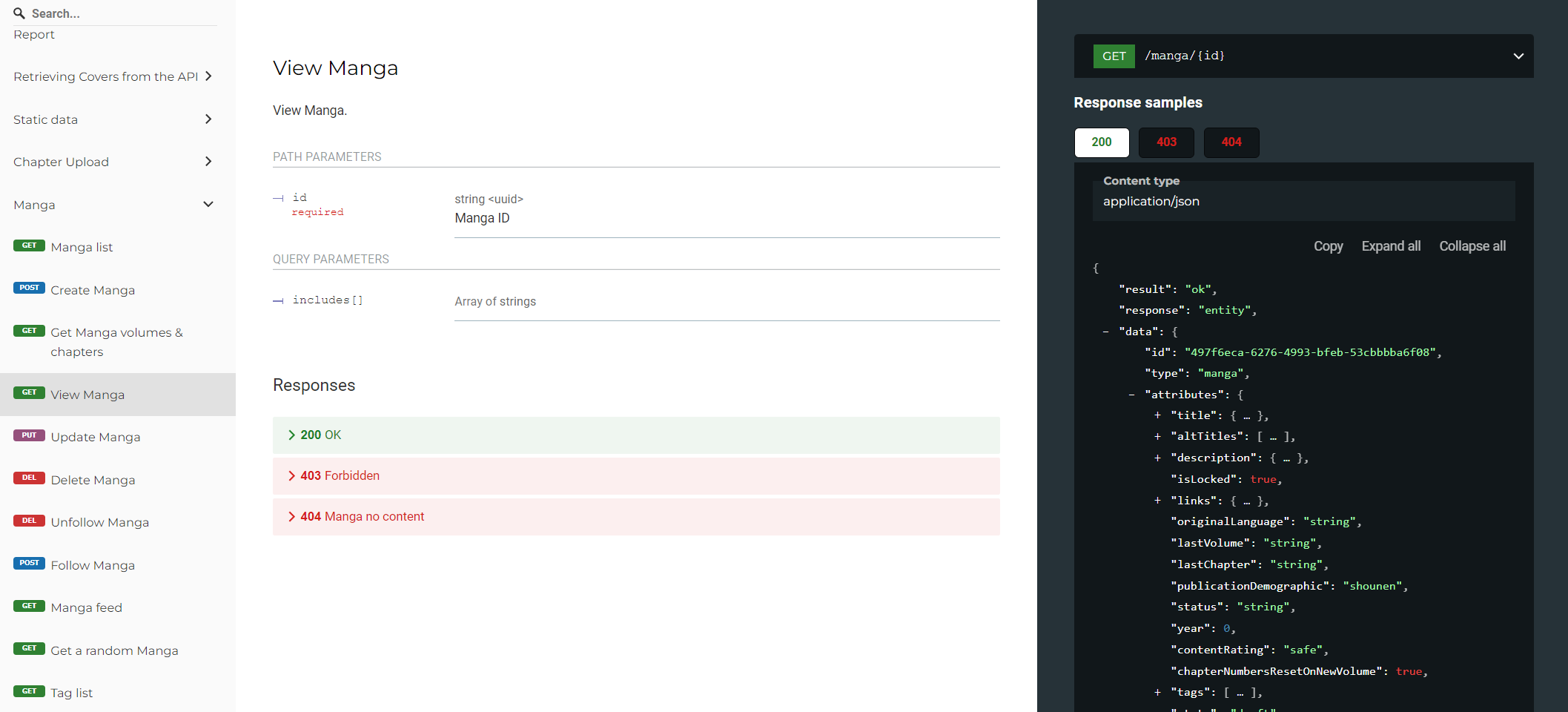
With all of this, if we follow a real request to get a Manga resource (using the GET /manga/:id endpoint) the request will be handled according to the following flow.
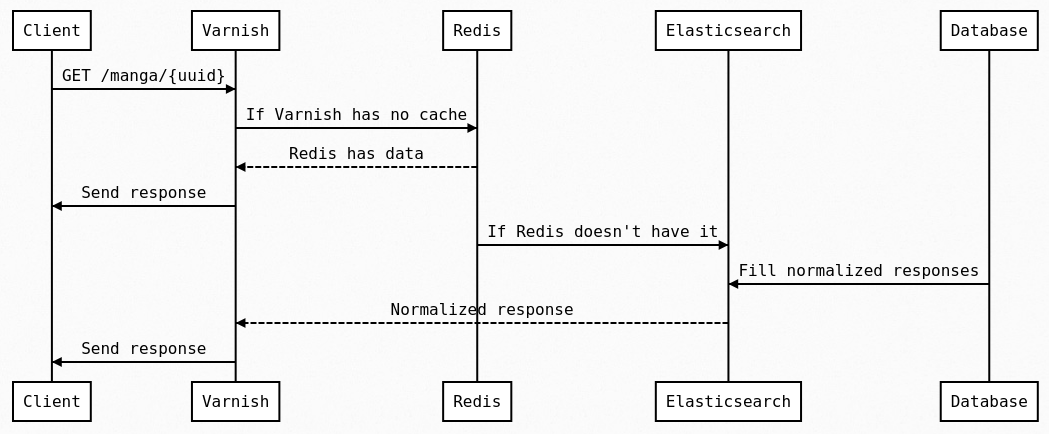
We check, in order, Varnish then Redis and finally Elasticsearch. While the Database is present in this schema, it is never hit synchronously for public entities as Elasticsearch is continuously updated by the backend to contain all of those.

Varnish is a layer 7⁶ cache so its main utility is to avoid making the trip from the edge to our servers and to avoid using FPM processes for something that can be publicly cached.
Every time you do a request on something cacheable on the API it will go through Varnish and forwarded to our main servers only if does not exist in its cache already. It will then be added as your request is processed, so the next one will use that cache, which is nearly free for us to serve, and closer to you (and thus faster).
We currently use a 1 month TTL on this cache to ensure the highest hit rate we can; however, this means that we need to notify Varnish that a resource is outdated, as it will serve it from its cache without ever checking with our API again otherwise. Using VCL (Varnish Configuration Language) we can add many custom behaviours and implement such a notification system. We added an extra HTTP verb, BAN, which is used to evict cached resources, forcing Varnish to fetch the resource from our API the next time it receives a request for it⁷.
To efficiently specify groups of entries to remove, we tag API responses based on the entities they contain, with the following scheme: {type}-{uuid:8}.
Cache-Tags ~ chapter-496c88fc
The type denotes the category of resource (ie. manga, chapter, group ...) and it is followed by the 8 first characters of the resource UUID, collisions here being an acceptable tradeoff for space as they are rather marginal. Indeed, we use UUID v4, so that prefix is largely random; in the example above, despite more than a million chapters, there is no collision. For collections, it's almost the same but we list all of the tags of contained items.
Thanks to this when a resource is updated, we send a BAN request to Varnish specifying the tags to evict, which leads to the resource, related resources and collections including it being evicted all in a single short eviction query.
If Varnish doesn't have the page in cache, the request is forwarded to our API servers. They first check if the resource exists in Redis, and if it is the case then that copy is returned as-is. Otherwise, Elasticsearch is queried to fetch the document (or documents), then its response is saved in Redis and sent back to the client.
Now you could ask why we have this cache in addition to Varnish? It is because when you use includes with an API call, we must fetch all the relationship objects and store them in Redis so they can be found faster on the next includes calls as this is otherwise an expensive about of subqueries to issue to Elasticsearch. This also applies to resources to a lesser extent. We have no TTL in Redis because we also dynamically replace/remove resources that are updated/deleted. We could do the same in Varnish but we prefered to put 1 month at first, though we have yet to go through a whole month without wiping it, as new features or changes regularly require us to evict those caches, which isn't a problem as we don't need them for the site to run and they only take an hour or so to fill again up to their average hit rate.
All these cache layers allow us to have fast responses time while not burning servers. They also make all non-private requests nearly free for us and faster for users.
In the past, every Wednesday the weekly release of Solo Leveling would cause massive load spikes and/or bring the site down. This is no longer an issue, and if we had a redo, our edge Varnish instances alone would largely handle all of that (with the help of MangaDex@Home for image delivery).
It's also not possible anymore since Solo Leveling is dead.
Future considerations
We have some stuff we would like to add to the API so here is a quick list and how it could help us:
- OAuth: At the moment we are using JWT token authentication that is managed within the API. Even if it's entirely safe to do it that way and our system has proven robust and reliable, we want to enable using your MangaDex account for the forums and/or other platforms eventually. So we need OAuth in order to have a single point of authentication. While all the details of how we will implement it are not clear, we also would like to introduce application tokens so we can track who is using the API and how.
- Timeseries: We would like to add a timeseries database in order to save the manga, chapter, ... views in real time. We already tried it before with Timescale but it wasn't good enough in terms of performance at our scale and with our limited hardware. We have other candidates and hope they will fit our usage!
- Feeds: This is something we didn't talk about in this post, but feeds are the most expensive request that we have at the moment on MangaDex. And every user has a unique feed based on the titles they are following so it is close to impossible to cache in the same way as other resources. We have some ideas to change that into a mix of pre-computed and on-demand lookups, similarly to how Twitter is handling timelines⁸ which would be a much more scalable long-term solution.
Conclusion
This concludes this blogpost about the security and data layers of the MangaDex API, I hope you learned during it and that you enjoy using our website!
- PHP6 was an attempt to make a PHP version with full Unicode compatibility: wikipedia.org/wiki/PHP#PHP_6_and_Unicode.
- PHP tags in HTML were a common practice in early PHP days (until PHP5) but nowadays are considered a very bad practice at least, a sacrilege at worst.
- Yes, in Symfony you will be always authenticated, even when anonymous, which allows us to wire roles & permissions to an anonymous user and allow other checks.
- PHP-FPM is a FastCGI implementation for PHP using its SAPI that we use on our servers. When an FPM process is locked it will cost CPU time; that's why we want it to be unlocked as soon as possible.
- You can read more about setting up a master-slave database deployment in this nice blogpost.
- Layers of the OSI model are a way to describe network communications. Layer 7 is the application layer, in our case it's represented by the HTTP protocol.
- Here is an example from some popular PHP HTTP caching library: ban.vcl.
- A good article I found on the subject of Twitter precomputed timelines.